Computers
- which typically echoes what you're doing with the mouse as text commands - these are, in fact, the commands you would type if you were FTP-ing from a command line (mostly, you can ignore them).
- the local directory, which is typically on the left. these are the folders from which you wish to move information onto the web.
- the remote directory, where you will be putting files.
- email - an electronic mail message
- listserv - a list server is a program that keeps track of mailing lists (a collection of emails), and manages the flow of emails coming and going. Basically, it allows you to send a message to one email address, and have many people receive that email. Sometimes these lists are broadcast (announcements, class notes, all spam), and sometimes they're two-way — you can reply to the author, or sometimes to the entire group.
- usenet - also called a news server. Most web browsers have a usenet or news viewer, and the news groups (or usenet groups) are a potentially wondrous source of information. There are literally tens of thousands of news groups - no matter what topic you're interested in, there's a news group for it. Dejanews is a web site that allows searches and queries, and will show you recent news group posting on a web page. Usenet was around way before the web, but sadly, with the advent of spam, many usenet groups are flood with garbage postings.
- BBN's - Also called bulletin boards. BBN's work just like usenet, but require a BBN program, and usually have a specific phone number you dial in order to access the server.
- discussion, forum - these are web-based programs that work much like usenet - they allow a user to read through topics and postings, reply to available messages, post new messages, and in some cases, start new topics of conversation.
- chat, i-messaging - a way to send a message instantly on the web. These programs require that their users "register" themselves when online - that is, the client program (that you use) tells the server when you're on line.
1's and 0's
Bits, bytes, binary - man, what's the deal? In the world of technology, only information matters. And in the world of computers, every piece of information is encoded in numbers. This shift in perspective has been a long time coming. You can argue that it started with Alexander Graham Bell's telegraph, which sent messages with electricity and effectively reduced the distance between any two people to zero. Or that it was the Gutenberg press, giving everyone the ability to store and disseminate knowledge widely. Or even that it came with the advent of language, of first learning to encode information and transmit it at all.
I think Gödel started the trend to numbers - in the process of demonstrating something fundamental about mathematics, he managed to express a more sweeping truth that applies to logic, to language, and ultimately, to how we think and what we are. And he did it all with numbers. Then Turing leapt in, and realized that the simplest system for encoding things mechanically was on / off - thus the 1's and 0's of binary computing came into being (Turing did a lot more than that, but he started the 1,0 thing).
This is a somewhat foreshortened version of computer history, I realize. But, for the purposes of design, what you need to know is that to a computer, everything is a number, and that ultimately, every kind of number can be converted to a binary ("bi" being latin for two - binary has two digits, 0 and 1).
Now, (assuming you're still reading), you're thinking, man, did I wander into the wrong lecture? Where's the design lesson here, and what's all that math I see down there? First and foremost, if you're using a computer to design, I believe it's fundamentally important to have some (possibly vague ≶grin>) understanding of the tool you're using. Design is a process in your head - the computer is one tool you can use, and programs such as Photoshop, Quark, Illustrator and Dreamweaver are also merely tools. There is absolutely nothing that any of these tools do that you cannot find some other way to accomplish, though it might be significantly more work. It is all too common to see designs that were clearly produced with electronic tools - people learn to design around the tool, instead of finding the appropriate tool with which to design, or learning how to correctly use a tool to build what's in their head. Great designers think through their tools and media, not with them.
Equally important is that because the computer uses numbers for everything, so do its tools. Photoshop and Netscape both express colors in numbers called hexadecimal. The printing world uses a different set of numbers - the Pantone system. The goal is the same - to define a color in a reproducible way, so that everyone seeing the color you picked is seeing the same color.
So, a quick review: we count in decimal ("deci" being latin for ten), most likely because we have 10 fingers and ten toes. Decimal works like this - each number has some digits. Each digit can have ten values - 0, 1, 2, 3, 4, 5, 6, 7, 8, 9. Combining digits means multiplying by 10:
= 1x10^2 + 9x10^1 + 8x10^0
= 1x100 + 9x10 + 8x1
Yeah, I know you know that. But it's helpful to remind oneself how it works, so you can understand binary. In binary, each number has some digits. Each digit can have only two values - 0, 1. We call these "binary digits," or bits. Combining digits means multiplying by 2 instead of 10, but the effect is the same:
= 1x2^7 + 0x2&6 + 1x2^5 + 1x2^4 + 0x2^3 + 0*2^2 + 1x2^1 + 1x2^0
= 1x128 + 0x64 + 1x32 + 1x16 + 0*8 + 0x4 + 1x2 + 1*1
= 179 (in decimal)
Computers read numbers the way we read words - in discrete chunks. The difference is that our words can have any number of letters, but for computers, every "word" they read is the same size, it has the same number of digits. For a long time, all computers read things 8 bits at a time, and we coined the word "byte", which means 8 bits - bytes are to computers as words are to human languages. The maximum value of one byte (8 bits) is 11111111, which equals 255 decimal. One tricky thing about counting in binary - everything starts with 0. So, although the maximum value a byte can hold is 255, it can hold 256 possible values (including 0). So, the maximum value of 8 bits is 2^8, or 256. This is why, for instance, the lowest resolution of your monitor is 256 colors (as opposed to 100, or 1000, or something that "makes more sense"). Or why there are approximately 256 colors in a GIF - because it takes exactly one byte to store the particular color for a particular pixel (more on color, GIFs, and images in the next lecture).
Everything in the computer world comes in multiples of two - 8 bits is a byte (8 = 2^4, or 4 bits); monitors with "thousands of colors" actually have 65,536 colors (2^16, or two bytes); you can have 64 "Megs of RAM", which means 64 million mega-bytes of RAM ("mega" meaning million, RAM meaning Random Access Memory); and so on. It's all about two.
You can actually use any number as a base in which to count - we use base 10, computers use base 2, you can use base 11, base 99, whatever. If you want to count more than 10 values per digit, you have to use some other set of symbols (since we only have 10 digits at our disposal). For instance, base 16 works the same as binary and decimal, with these digits: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F; where A thru F means 10 through 15 in decimal, respectively. As a quick aside, binary is easy to spot, and so is decimal. But, if you have a small hexadecimal number, such as 12345, how can you tell that it's hexadecimal? Typically, it is preceded by the pound sign, like ze so: #12345, or #A321F3. Another example:
= Ax16^5 + 3x16^4 + 2x16^3 + 1x16^2 + F*16^1 + 3x16^0
= 10x1,048,576 + 3x65,536 + 2x4096 + 1x256 + 15*16 + 3x1
= 10,691,059 (in decimal)
As you can see, it's possible to "store" a much bigger number with much fewer digits in hexadecimal.
bringing it home
Now, take a second to look at your Photoshop color picker:
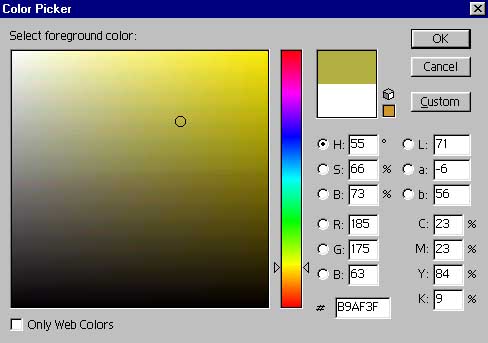 Typically, people use this by moving around the vertical slider and picking a color by clicking in the big square of color on the left. But, all colors can be broken down into components, typically either CMYK or RGB. In printing (which tends to use CMYK), color is "subtractive" - using 100% of cyan, magenta and yellow ink produces black. In light (as in televisions and computer monitors), color is additive - 100% red, green and blue produces white. In both cases, you combine different amounts of each major color to produce the resulting shade.
Typically, people use this by moving around the vertical slider and picking a color by clicking in the big square of color on the left. But, all colors can be broken down into components, typically either CMYK or RGB. In printing (which tends to use CMYK), color is "subtractive" - using 100% of cyan, magenta and yellow ink produces black. In light (as in televisions and computer monitors), color is additive - 100% red, green and blue produces white. In both cases, you combine different amounts of each major color to produce the resulting shade.
This is easy enough to see - picking any color on the left immediately fills in the R, G and B values on the lower right. This works the other way as well - you can fill in RGB values to get a particular color. It's important to note that the RGB values must be < 255 - Photoshop will force the number to 255 if you enter anything larger. Hopefully, you'll recognize that 255 is the maximum value of one byte - thus, photoshop uses one byte to store red valuation, one for blue, and one for green - it takes three bytes of information to express the color of each individual image in Photoshop (more on this in the next lecture).
Directly below the RGB values is a box with a "#" in front of it, which, naturally, you will immediately recognize as being a hexadecimal number (see how it all comes together?). Now, here's the interesting part — although you can think of the hexadecimal as one number out of 16,777,216 possible combinations (#FFFFFF = 16,777,215), it is in fact an RGB value. Thus, #B9AF3F breaks up into #B9 (185 decimal), #AF (175 decimal), and #3F (63 decimal) - exactly the same as the R, G and B values above it!
This is all a bit easier to understand visually:
![]()
Having a clear grasp of the numbers underlying the colors you pick, and how they will reproduce on the medium you intend is key to any good design. If it doesn't look the same to everyone else as it does to you, you've failed to get your message across, and missed the entire purpose of design.
insert tab A into slot B
In order to understand how to design for the web, you have to understand what the web is, and what the internet is. Technically, I suppose you could design for the web without understanding it all, but practically, you have to have at least a vague grasp of networks in order to build and maintain a web site.
The internet does not exist — it runs solely on faith.
No, I'm not talking about a giant government conspiracy/hoax scheme (although a few senators still seem to think so). And this is definitely not a religious tract. There is no 'thing' that is the internet. Every single computer that's linked into the whole helps make up the internet (including the one you're on right now). By dialing in and reading this, you have expanded the net. It does not rely on any central computer or specific piece, it is the term used to describe the collection of all the cables and all the phone lines and all the computers that are simultaneously hooked together right now. And no one runs it. Not the Uncle Sam, not Big Bill, not nobody.
Originally, the internet was a series of computers connected remotely (probably over dedicated phone lines); it was built by ARPA (Advanced Research Projects Agency — an arm of the US Defense Dept.) So it was built by the U.S. government. But it was designed in such a way that any piece in the network can be removed — any phone line, any computer — and the rest of it still works. It was actually designed to survive a nuclear war. Somewhat recently, the US Government removed their last computer from the network — and it was a biggy — and nothing happened. Nothing at all.
Essentially, the internet relies on protocols — predefined electronic means of communication. Protocols can be very simple. When you were five, and you called the front seat, you got the front seat. That's a protocol. The internet relies a large number of protocols that allow all the machines to communicate; protocols such as TCP/IP, FTP, HTTP, Gopher, Archie. These are all acronyms that describe the kind of information that's being exchanged, and who or what is exchanging it.
Take TCP/IP for instance. It's one of the most basic protocols - Transfer Control Protocol / Internet Protocol — simple, right? That just means that it describes the way that that two or more machines that are interconnected over a network are going to agree to transfer information back and forth.
That's where the faith comes in: in order for the system to work correctly, every single computer has to exchange all its information with every other computer in exactly the same way, or it won't work. It's pretty amazing how it all works together. And it works because individuals define new protocols, ones that are really good. They hand them out, and everyone agrees that they're good, then everyone agrees to make all their products use those protocols, and they talk together.
Tim Berners Lee defined HTML in the early 90's, and HTML (Hyper Text Markup Language) is what defines the shape and position of the things on this page. You can see the page as I want you to see it because no matter what software you use (Netscape, Internet Explorer, AOL, Opera....), it understands how to draw this page, because it's using the HTML standard. Note that HTTP (Hyper Text Transfer Protocol) is a protocol (a set of rules for how information is exchanged) and HTML is a standard (a set of rules for how a set of information, such as a file is actually arranged).
I should probably tell you that technically, the web and the internet are not quite the same thing. "The internet" is an all-encompassing term referring to all the electronic devices currently communicating via TCP/IP; "the web" actually refers to graphical pages such as the one you're looking at. However, I and everybody else now use the term net, internet, and web to refer to pretty much the same thing - what you're seeing through your browser.
Believe it or not, there are other ways to look at information on the internet. Email is a perfect example. It's a kind of information that's being exchanged, defined by the SMTP protocol (Simple Mail Transfer Protocol) which is viewed with a mail-reading program, not a browser. Programs like Netscape now allow you to see web pages, send mail, and download files (FTP - File Transfer Protocol), thus blurring the lines and allowing you to "surf the net," no matter what kind of information your sending and receiving (for a bit more detail on the internet and how it works, try here).
The other major factor you need to be aware of is how you're actually connected to the internet; there are two primary methods - PPP (Point to Point Protocol and LAN's (Local Area Networks. A PPP connection is what you have when you dial an internet service provider (ISP) with a modem - it's a protocol that allows two (and only two) computers to talk with each other. Once a PPP connection is established, your computer can speak TCP/IP over the PPP connection with the rest of the net. LAN's are essentially mini internets - a localized collection of computers that may or may not be connected to the internet proper, and which speak a specialized language (LAN's have their own protocol).
The key is this - in order to be part of a TCP/IP network (e.g. the internet), your computer must have a unique TCP/IP number, such as 207.222.122.001. These are the internet equivalent of phone numbers. When you dial up or access the internet via a LAN, you are (in most cases) temporarily assigned a unique number for the duration of your session from a pool of numbers that your ISP holds.
| WEB PAGE |
| HTML |
| HTTP |
| TCP |
| IP |
| PPP or LAN |
| copper and silicon |
you go first. no please, you go first.
Everything on the net works on the very simple principle of question and response, generally called "client - server relationship." What this means is that there are always at least two computers, and one is making the request, and the other is responding to it. Ironically, this is the model used by mainframe computers long before the personal computer ever arrived, and the web has brought us full circle. Technically, any computer making a request is the client, and any computer answering a request is the server; however, for most purposes, the server is the computer that is hosting the web site that which you're looking at with your computer.
To be a bit more specific, the "client" isn't your computer, but the software program you are using. Thus, Netscape and Explorer are clients - they allow you to see remote data in a specific format. Practically speaking, all the software you use is a form of client; there is a window, within which you work, and your instructions (typing, pointing and clicking) are fed to the application. The application functions as a sort of server, returning responses to your browser or desktop window. Eventually, virtually all the software you use will be a literal server - programs like Photoshop will run remotely, and you will access them through a window via the internet.
The primary advantages of this model are 1) instead of many many copies of a program running on many different computers, a single copy is owned and maintained on an individual server (or on several servers), which helps guarantee that everyone is using the latest and best version of the same software; and 2) your computer is only responsible for taking instructions (from you), and rendering the results (what happens after you click), but not the hard processing that produces the results.
What becomes important from a design perspective is the basic nature of dynamic interaction — unlike all other media, which are inherently broadcast media by nature, the internet involves the user making choices. The internet is a dynamic, non-linear medium. This is so important, we're going to spend an entire lecture on it.
the shell game
One of the primary benefits of the internet is the ability to move files around, and to allow remote viewing of data. In order to serve up a web site, you have to have a computer connected to the internet. However, you also need a fixed IP address, which is why it's difficult if not impossible to serve a web site from a dial-in computer. Obviously, there are also performance, maintenance and security issues associated with having a web server, which is why you typically pay someone else to solve that problem. There are even free places to host web pages, though the price you pay is the advertising that will become a part of your site, and the advertising you'll receive for signing up.
There are three major ways to move files, and issue remote commands to another computer. They are:
FTP | File Transfer Protocol |
telnet | A remote shell |
SSH | A Secure remote SHell |
A shell is a window in which you can type commands to an operating system, such as Macintosh (OS X only), Windows (at the DOS prompt), or Unix (e.g. FreeBSD, Linux, etc.). It's also referred to as the "command line", because it's a line upon which you type commands (about which Neal Stephenson has written a hilarious and very informative book, which I highly recommend). A shell is also a client, talking to an operating system (OS) as its server. That OS could be on the same physical machine, or a remote machine - the shell doesn't care, although you have to have access permission or an account in order to use a shell for a remote machine.
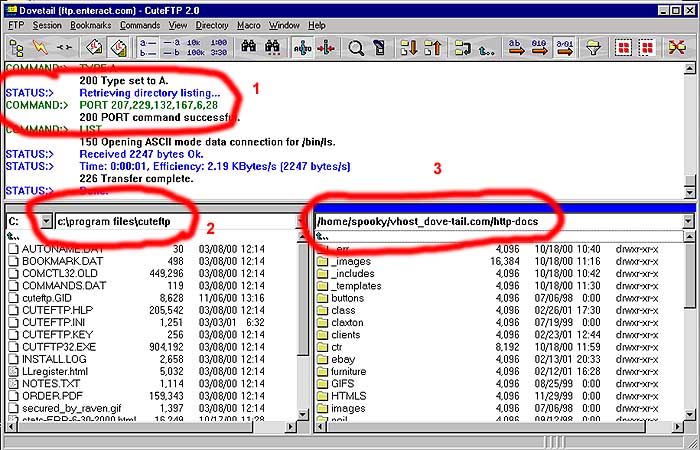
FTP is the most common tool for moving files around on the internet. If, for instance, you use Dreamweaver's tools for uploading and downloading web sites, you are using an FTP client. Most FTP clients work the same way. There are three windows:
Generally, you drag files and folders from left to right to upload them, right to left to download them. For more info on how to FTP things, and some good rules to follow, jump over here.
you want a what now?
There are a host of ways to communicate on the internet. Some of them you've already used, some you'll use eventually, but you should ultimately know about all of them, as each can be a valuable tool when creating a web site. This is especially true if you expect to allow users to have some kind of ongoing conversation. A quick list includes:
a square peg in a round hole
Even though you get to point and click your way around a computer and the web, the computer has to keep careful track of where everything is at. The two primary way to refer to things is via file path, and via URL. URL stands for Uniform Resource Locator - it's a way of referencing a file so that it can always be found on the internet. Specifically, a URL (sometimes referred to as a URI) looks like http://www.something.com/, or more frequently http://www.something.com/folder/folder/filename.ext.
Behind the scenes, www.something.com gets translated to an IP address (e.g. 111.222.333.444) - the computer equivalent of a phone number. It's a number that refers to some specific computer on the internet - your computer has a unique IP as well (although it could be assigned by your ISP for the duration of your session, or you could be sharing an IP on a LAN).
Web pages can contain content from many places on the internet - not all content has to be on the same computer. For instance, you can have a page on your server, with an image (that appears on the page) actually being stored on another server. It's also common to have many files and images stored in different folders for organizational purposes (or for security reasons).
The key thing to know here is the difference between absolute and relative path names, because it affects the way things look on your computer relative to way they will look on the web server. Absolute path names are names that start from the "top" of a file system:
Mac - harddrive/class/website/index.htm
Unix - /Windows/Desktop/class/website/index.htm
These examples are absolute - they start from the root of the operating system and go down. Relative path names start from the folder in which the file is found:
This might be the path name to a start button image, found under the images folder, which is (in this case) located in the folder that the html is in. Sometimes, you'll see path names that contain dots, like this:
./images/buttons/start.gif
A single dot means "start in the folder that I am in," a double dot means "go up one folder." This is a bit clearer if you see the file system:
-
html/
- images/
- buttons/
- start.gif
end.gif
- recent/
- computers.htm
design.htm
So, if design.htm wants to use an image in the images folder, it can reference that image in one of two ways, absolute or relative:
relative ../../images/buttons/start.gif
Obviously, relative is shorter in this case. However, the important issue is this - when you move your web site to a remote web server, the absolute path name will change, because the various directories between your web site and the server's root address will be different, perhaps like this:
This is why web pages need to use relative addressing. Except for this one little catch: There's also something called "web-relative addressing." What happens is that the web server "knows" that all web requests "start" in a particular folder - this is for security reasons, in order to prevent someone on the web to see every file on a server. In our above example, the "html" folder is the "web root" - the root folder for all web requests. Essentially, the web server software "pretends" that everything above this folder does not exist. So that this:
Looks like this to all the web users:
Notice how the "/" appears at the beginning of the path name? The rest of the path up to the "html" folder is implied, and the html folder itself functions as the root folder. This is handy when designing a web site, because you can always "jump" to the top of your web directory structure by putting a "/" at the beginning of a file path. It also usually means that your site won't look right on your local machine, because your local machine is trying to start at the top of its own directory structure, instead of from within your root web folder.